이전 사진 뒤져보니 2002년 9월 즈음에도 망가져서 수리했는데
4년만에 또 뽀각 -_-
통합핸들 일반형
음.. 이게 왜 핸들이여?!?!?

[링크 : https://yylxzin.co.kr/goods/goods_view.php?goodsNo=1000000008]
이전 사진 뒤져보니 2002년 9월 즈음에도 망가져서 수리했는데
4년만에 또 뽀각 -_-
통합핸들 일반형
음.. 이게 왜 핸들이여?!?!?
[링크 : https://yylxzin.co.kr/goods/goods_view.php?goodsNo=1000000008]
문제 없이 설치되는데
재시작 하면 부팅할 매체를 찾지 못한다.
혹시나 해서 다시 설치 usb로 켜서
gparted 에서 bios_grub 라는 flag 에서
boot로 바꾸었더니 boot + esp가 활성화 되는데
이렇게 해도 안된다. 혹시 uefi가 정상적으로 지원되지 않는 바이오스라 그런건가..?
| ubuntu 22.04 24.04 설치 파티션 차이 (0) | 2026.07.09 |
|---|---|
| ubuntu 26.04 + 595.71.05 + CUDA 13.2 (0) | 2026.06.17 |
| festival - a text-to-speech system(tts) (0) | 2026.05.06 |
| luit (0) | 2026.03.23 |
| ubuntu 22.04 bgr 패널 대응 (0) | 2025.12.29 |
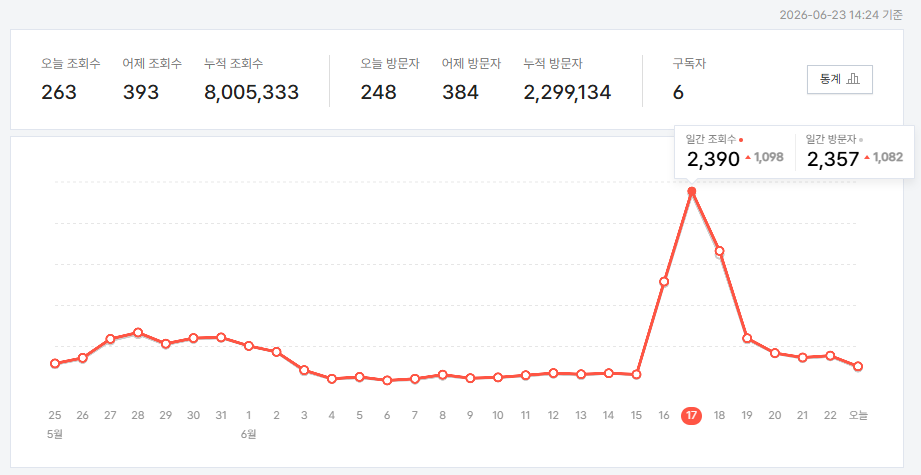
주말이라도 안쉬고 했는데 떨어질건 떨어짐 ㅋㅋㅋ
그냥 한달에 한번 씨게(!) 긁어서 업데이트 하는 느낌(RAG db)
| 불법촬영물 여부 검토 (2) | 2026.07.24 |
|---|---|
| 한 달에 한 번? (0) | 2026.06.17 |
| 개인정보 유출 통지 - 데이원 컴퍼니 <- 콜로소 (2) | 2026.06.11 |
| 잠깐의 행복했던 방문자 수 (0) | 2026.06.08 |
| 도메인 결제 (4) | 2026.06.01 |
그냥 깔면 알아서 업데이트 된...다?

ISO 파일은 바뀌지 않고 안전하다고 하니 일단 ㄱㄱ

우옹

어? 26.04가 아니라 24.04.4 설치 실패 버그픽스????
|
| trickle - 대역폭 제한 (0) | 2026.07.28 |
|---|---|
| gary's mod - 게리모드 (0) | 2026.06.24 |
| microhttpd (0) | 2026.06.05 |
| tmux (0) | 2026.05.11 |
| appimage , AppImageLauncher (0) | 2026.04.20 |
이게 먼소리여..
유니버셜 로봇 강의 가서
다른 사람들이 손가락으로 막 이상한 짓(?) 하고 있어서
웬지 좌표계 같아서 찾아보는데 이해가 안된다 ㅠㅠ
좀 보다 보니..
오른손 좌표계에서
축 증가방향 - 엄지(x) 검지(y) 중지(z)
축 회전방향 - 따봉했을때 검지-중지-약지-새끼 의 방향

| mycobot280 pi / TCP(tool center point) (0) | 2026.06.30 |
|---|---|
| mycobot 280 pi / python (0) | 2026.06.29 |
| mycobot280_pi urdf (0) | 2026.06.22 |
| 블루로봇 밸런스 스테이지 (0) | 2026.06.21 |
| elephant robotics cobot python api (0) | 2026.06.19 |
URDF 포맷의 정보를 이용하면 관절관의 거리 등이 있어서
ROS2 나 moveit2 에서 충돌 검사를 통해서 자기 파괴하지 않도록 할 수 있다고 한다.
moveit은 ros 1용
moveit2는 ros 2 용인듯. 그런데 단독 사용은 안되려나?
[링크 : https://github.com/moveit/moveit2]
| <?xml version="1.0"?> <robot xmlns:xacro="http://www.ros.org/wiki/xacro" name="firefighter" > <xacro:property name="width" value=".2" /> <link name="g_base"> <visual> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/G_base.dae"/> </geometry> <origin xyz = "0.0 0 -0.03" rpy = "0 0 1.5708"/> </visual> <collision> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/G_base.dae"/> </geometry> <origin xyz = "0.0 0 -0.03" rpy = "0 0 1.5708"/> </collision> </link> <link name="joint1"> <visual> <geometry> <!--- 0.0 0 -0.04 1.5708 3.14159--> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint1_pi.dae"/> </geometry> <origin xyz = "0.0 0 0 " rpy = " 0 0 0"/> </visual> <collision> <geometry> <!--- 0.0 0 -0.04 1.5708 3.14159--> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint1_pi.dae"/> </geometry> <origin xyz = "0.0 0 0 " rpy = " 0 0 0"/> </collision> </link> <link name="joint2"> <visual> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint2.dae"/> </geometry> <origin xyz = "0.0 0 -0.06096 " rpy = " 0 0 -1.5708"/> </visual> <collision> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint2.dae"/> </geometry> <origin xyz = "0.0 0 -0.06096 " rpy = " 0 0 -1.5708"/> </collision> </link> <link name="joint3"> <visual> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint3.dae"/> </geometry> <origin xyz = "0.0 0 0.03256 " rpy = " 0 -1.5708 0"/> </visual> <collision> <geometry> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint3.dae"/> </geometry> <origin xyz = "0.0 0 0.03256 " rpy = " 0 -1.5708 0"/> </collision> </link> <link name="joint4"> <visual> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint4.dae"/> </geometry> <origin xyz = "0.0 0 0.03056 " rpy = " 0 -1.5708 0"/> </visual> <collision> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint4.dae"/> </geometry> <origin xyz = "0.0 0 0.03056 " rpy = " 0 -1.5708 0"/> </collision> </link> <link name="joint5"> <visual> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint5.dae"/> </geometry> <origin xyz = "0.0 -0.001 -0.0345 " rpy = " 0 -1.5708 1.5708"/> </visual> <collision> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint5.dae"/> </geometry> <origin xyz = "0.0 -0.001 -0.0345 " rpy = " 0 -1.5708 1.5708"/> </collision> </link> <link name="joint6"> <visual> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint6.dae"/> </geometry> <origin xyz = "0 0.00 -0.038 " rpy = " 0 0 0"/> </visual> <collision> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint6.dae"/> </geometry> <origin xyz = "0 0.00 -0.038 " rpy = " 0 0 0"/> </collision> </link> <link name="joint6_flange"> <visual> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint7.dae"/> </geometry> <origin xyz = "0.0 0 -0.012 " rpy = " 0 0 0"/> </visual> <collision> <geometry> <!--- 0.0 0 -0.04 --> <mesh filename="package://mycobot_description/urdf/mycobot_280_pi/joint7.dae"/> </geometry> <origin xyz = "0.0 0 -0.012 " rpy = " 0 0 0"/> </collision> </link> <joint name="g_base_to_joint1" type="fixed"> <axis xyz="0 0 0"/> <limit effort = "1000.0" lower = "-3.14" upper = "3.14159" velocity = "0"/> <parent link="g_base"/> <child link="joint1"/> <origin xyz= "0 0 0" rpy = "0 0 0"/> </joint> <joint name="joint2_to_joint1" type="revolute"> <axis xyz="0 0 1"/> <limit effort = "1000.0" lower = "-2.9321" upper = "2.9321" velocity = "0"/> <parent link="joint1"/> <child link="joint2"/> <origin xyz= "0 0 0.13956" rpy = "0 0 0"/> </joint> <joint name="joint3_to_joint2" type="revolute"> <axis xyz="0 0 1"/> <limit effort = "1000.0" lower = "-2.4434" upper = "2.4434" velocity = "0"/> <parent link="joint2"/> <child link="joint3"/> <origin xyz= "0 0 -0.001" rpy = "0 1.5708 -1.5708"/> </joint> <joint name="joint4_to_joint3" type="revolute"> <axis xyz=" 0 0 1"/> <limit effort = "1000.0" lower = "-2.6179" upper = "2.6179" velocity = "0"/> <parent link="joint3"/> <child link="joint4"/> <origin xyz= " -0.1104 0 0 " rpy = "0 0 0"/> </joint> <joint name="joint5_to_joint4" type="revolute"> <axis xyz=" 0 0 1"/> <limit effort = "1000.0" lower = "-2.6179" upper = "2.6179" velocity = "0"/> <parent link="joint4"/> <child link="joint5"/> <origin xyz= "-0.096 0 0.06462" rpy = "0 0 -1.5708"/> </joint> <joint name="joint6_to_joint5" type="revolute"> <axis xyz="0 0 1"/> <limit effort = "1000.0" lower = "-2.7052" upper = "2.7925" velocity = "0"/> <parent link="joint5"/> <child link="joint6"/> <origin xyz= "0 -0.07318 -0.001" rpy = "1.5708 -1.5708 0"/> </joint> <joint name="joint6output_to_joint6" type="revolute"> <axis xyz="0 0 1"/> <limit effort = "1000.0" lower = "-3.14" upper = "3.14159" velocity = "0"/> <parent link="joint6"/> <child link="joint6_flange"/> <origin xyz= "0 0.0456 0" rpy = "-1.5708 0 0"/> </joint> </robot> |
엥 ur5e 니가 왜 여기서 나와 -ㅁ-
[링크 : https://github.com/jdj2261/pykin]
[링크 : https://ropiens.tistory.com/177] << 볼 것 링크
| mycobot 280 pi / python (0) | 2026.06.29 |
|---|---|
| 왼손 오른손 좌표계 (0) | 2026.06.22 |
| 블루로봇 밸런스 스테이지 (0) | 2026.06.21 |
| elephant robotics cobot python api (0) | 2026.06.19 |
| elephant robotics mycobot 280 pi python 예제 (0) | 2026.06.16 |
AVR 때는 자주 쓴거 같은데
stm32 되면서 함수를 통해 1개 핀에 대해서만 바꾸다 보니 불편해서 찾아보는데
머.. 결국은 레지스터 건드릴 수 밖에 없는 듯
ODR 값 읽고 마스킹 후에 한번에 갈아 치우는게 나을 듯
| If you want the whole port (all 16 pins) get the value, then you simply write it to the ODR register: GPIOB->ODR = 0xFFFF; //writing 1/0 in a bit position, sets/resets that bit. ALL BITS ARE AFFECTED no matter the value your write in. If you want to set some pins, but not altering the other pins, with one instruction: GPIOB->BSRR = 0x00F; //writing 1 in a bit position, sets that bit leaves the others as they are If you want to reset some pins, but not altering the other pins, with one instruction: GPIOB->BRR = 0x00F; //writing 1 in a bit position, clears that bit and leaves the others as they are If you want a "portion" of a GPIO port to get an specific value, this method is 2 instructions instead of "read-change-write": GPIOB->BRR = 0x00F; //clear the first 4 bits GPIOB->BSRR = 0x00A; //set the desired bits in that 4-bit field |
ODR 정도는 low level 함수로 존재하나 보다.
| using LL API: LL_GPIO_WriteOutputPort(GPIOA,x); |
| wtite_bits(uint16_t cmd) { uint32_t data = GPIOA -> ODR; data &= ~(0x1fff); data |= cmd & 0x1fff; GPIOA -> ODR = data; data = GPIOB -> ODR; data &= ~(0x0007); data |= (cmd & 0x8fff) >> 13; GPIOB -> ODR = data; } |
[링크 : https://stackoverflow.com/questions/48365156/stm32f4-write-read-16bits-into-two-8-bit-gpio-port]
| stm32 uart data bit (0) | 2026.03.17 |
|---|---|
| stm32 다른 영역으로 점프(부트로더) (0) | 2026.03.06 |
| stm32cubeide cpp 변환이후 generate code (0) | 2026.02.25 |
| mbed + stm32cube hal...? (0) | 2026.02.23 |
| Mbed studio on ubuntu 22.04 (0) | 2026.02.23 |
유튜브 보다가 광고를 다 본건 또 첨이네 ㅋㅋㅋ
처음에는 이게 머하는 거여~ 싶었는데
보다보니 만져볼만큼 싼 곳에 들어갈 장비가 아니라는 느낌만 잔뜩~ 드는 녀석
[링크 : https://www.youtube.com/watch?v=jJ7jJ0ciF4g]
[링크 : https://www.youtube.com/watch?v=SKrBfwh6R_8]
[링크 : https://bluerobot.co.kr/]
아래는 유튜브 광고 찾기 ㅋㅋㅋ
[링크 : https://adstransparency.google.com/?platform=YOUTUBE®ion=KR]
[링크 : https://www.reddit.com/r/youtube/comments/1kajmpx/how_to_find_an_ad_i_saw/?tl=ko]
| 왼손 오른손 좌표계 (0) | 2026.06.22 |
|---|---|
| mycobot280_pi urdf (0) | 2026.06.22 |
| elephant robotics cobot python api (0) | 2026.06.19 |
| elephant robotics mycobot 280 pi python 예제 (0) | 2026.06.16 |
| 유니버셜 로봇 polyscope 5 (0) | 2026.06.16 |
로컬 LLM 에서 MCP 연결할 수 있으려나?
일일이 만드는것도 귀찮은데 만들어 둔 mcp 들을 쉽게 붙이면 좋을것 같긴하다.
결국은 json 타입으로 이해하기 쉽게 던져주면 알아서 쓴다.. 이런 컨셉이구나
| MCP 도구 목록을 LLM이 이해하는 JSON 형식으로 변환하기 MCP 서버에서 가져온 도구 목록은 그대로 LLM에게 전달할 수 없습니다. OpenAI Responses API가 이해할 수 있는 JSON 형식으로 변환해줘야 합니다. 다음은 그 변환 함수와 적용 예시입니다. |
[링크 : https://wikidocs.net/287840] fast mcp
[링크 : https://pypi.org/project/fastmcp/]
[링크 : https://raeul0304.tistory.com/9] mcp-use
| gemini cli 안녕~? (0) | 2026.07.01 |
|---|---|
| mogrify를 이용한 이미지 증강, 배경색 설정 (0) | 2026.06.25 |
| llama-swap 구현 (채팅) (0) | 2026.06.18 |
| gemma4-e4b mtp..? (0) | 2026.06.18 |
| openai api 변경에 따른 llama.cpp / llama-swap 리포트 차이 (0) | 2026.06.18 |
그래도 찾아는 보자
[링크 : https://github.com/jhacksman/OpenSCAD-MCP-Server]
| openSCAD + claude.ai = 파라메트릭 모델링 (0) | 2026.07.13 |
|---|---|
| pythonSCAD (0) | 2026.06.20 |
| openSCAD cheatsheet (0) | 2026.06.20 |
| openSCAD 설치 (0) | 2026.06.20 |
| openscad (0) | 2026.05.27 |

|