moviad에서 내가 만든 데이터를 증강(회전, 밝기) 해서 학습시키는데
(원본 5개, 증강 해서 250개로 뻥튀기)
| if "micronet" in model.student.model_name: optimizer = torch.optim.SGD( model.student.parameters(), 0.04, momentum=0.9, weight_decay=1e-4 ) else: optimizer = torch.optim.SGD( model.student.parameters(), 0.4, momentum=0.9, weight_decay=1e-4 ) |
0.4 (소스 코드 원래 값, 약 500 epoch)
값이 내려가지 못하고 계속 진동하면서 내려가려다가 훅 올라간다.
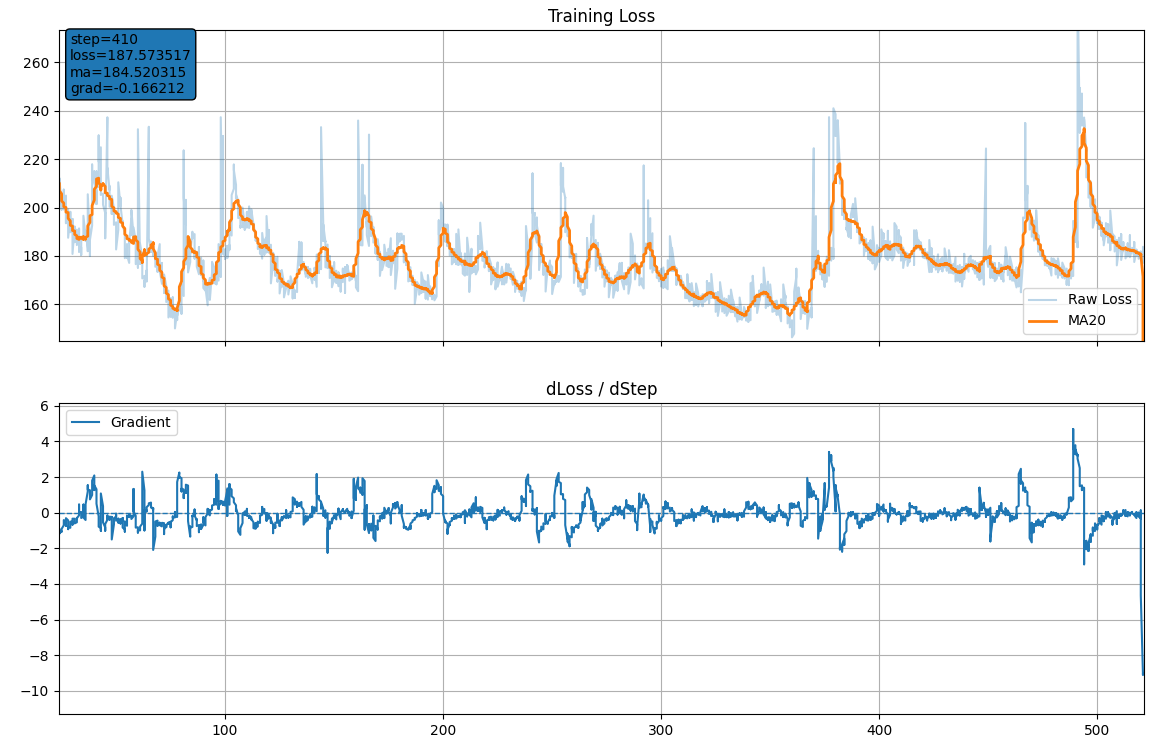
0.01(약 500 epoch)

반대로.. 데이터는 의외로 문제가 없다..인가?
[링크 : https://sevillabk.github.io/1-early-stopping/]
[링크 : https://wikidocs.net/137910]
loss 만 보고 있는데 accuracy 쪽도 출력하도록 수정해봐야겠다
'프로그램 사용 > yolo_tensorflow' 카테고리의 다른 글
| 딥러닝 학습 - trainig loss / validation loss (0) | 2026.07.16 |
|---|---|
| moviad ssd-mobilenetv2 on imx8mp (0) | 2026.06.24 |
| moviad / stftpm / 1080 ti / webcam feat claude (0) | 2026.06.19 |
| moviad stfpm (0) | 2026.06.18 |
| ubuntu 26.04 + 3070 + tensorflow + python 3.14 + docker... (0) | 2026.06.17 |