/dev/dsp는 OSS의 일부인데
해당 기능을 활성화 하려면 아래의 모듈을 불러오면 된다고
| # modprobe snd-pcm-oss |
아래처럼 하면 소리가 난다는 것 같다.
| sudo sh -c 'cat file.wav > /dev/dsp' |
[링크 : https://unix.stackexchange.com/questions/103746/why-wont-linux-let-me-play-with-dev-dsp]
+
2022.01.03
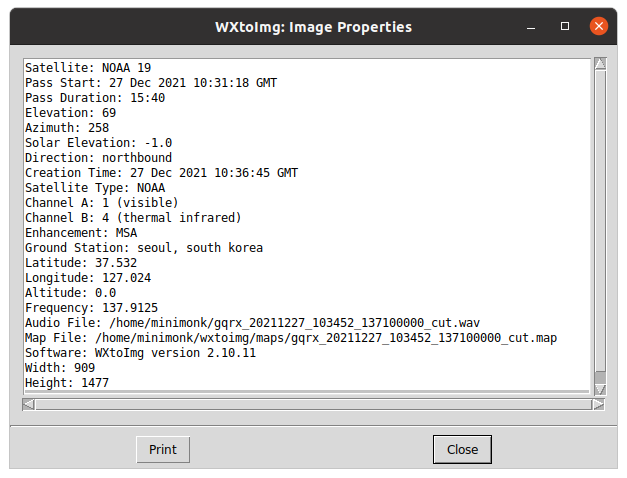
xwxtoimg 에서 해보려고 찾아두고는 얼마나 안해보고 있는거냐..
+
2022.06.08
ubuntu 18.04에서 시도해보았으나 동일한 모듈은 없고.
비슷한걸 찾아서 넣어봐도 /dev/dsp나 sound 등이 생성되진 않았다.
| $ grep -rni oss /lib/modules/5.4.0-113-generic/ /lib/modules/5.4.0-113-generic/modules.alias:26312:alias sound-service-?-0 snd_mixer_oss /lib/modules/5.4.0-113-generic/modules.order:1161:kernel/drivers/net/ethernet/alacritech/slicoss.ko /lib/modules/5.4.0-113-generic/modules.order:4550:kernel/sound/core/oss/snd-mixer-oss.ko $ sudo modprobe snd_mixer_oss $ lsmod | grep oss snd_mixer_oss 24576 0 snd 86016 18 snd_hda_codec_generic,snd_seq,snd_seq_device,snd_hda_codec_hdmi,snd_hwdep,snd_hda_intel,snd_hda_codec,snd_timer,snd_pcm,snd_hda_codec_idt,snd_rawmidi,snd_mixer_oss |
+
pulseaudio와 osspd 라는 녀석을 설치하니 뜬다!
| $ sudo apt-get install pulseaudio libpulse-dev osspd $ ls -al /dev/dsp crw-rw-rw- 1 root root 14, 3 6월 8 12:14 /dev/dsp |
[링크 : https://askubuntu.com/questions/1025532/initaudi-cannot-open-oss-audio-device-dev-dsp]
'프로그램 사용 > rtl-sdr' 카테고리의 다른 글
| rpi gqrx (0) | 2022.01.07 |
|---|---|
| rtl sdr am (0) | 2022.01.07 |
| rtl-sdr noaa 안테나 만들어서 재시도 (0) | 2021.12.27 |
| 부품 도착! + 공짜 도착! (2) | 2021.12.27 |
| wxtoimg linux (0) | 2021.12.26 |