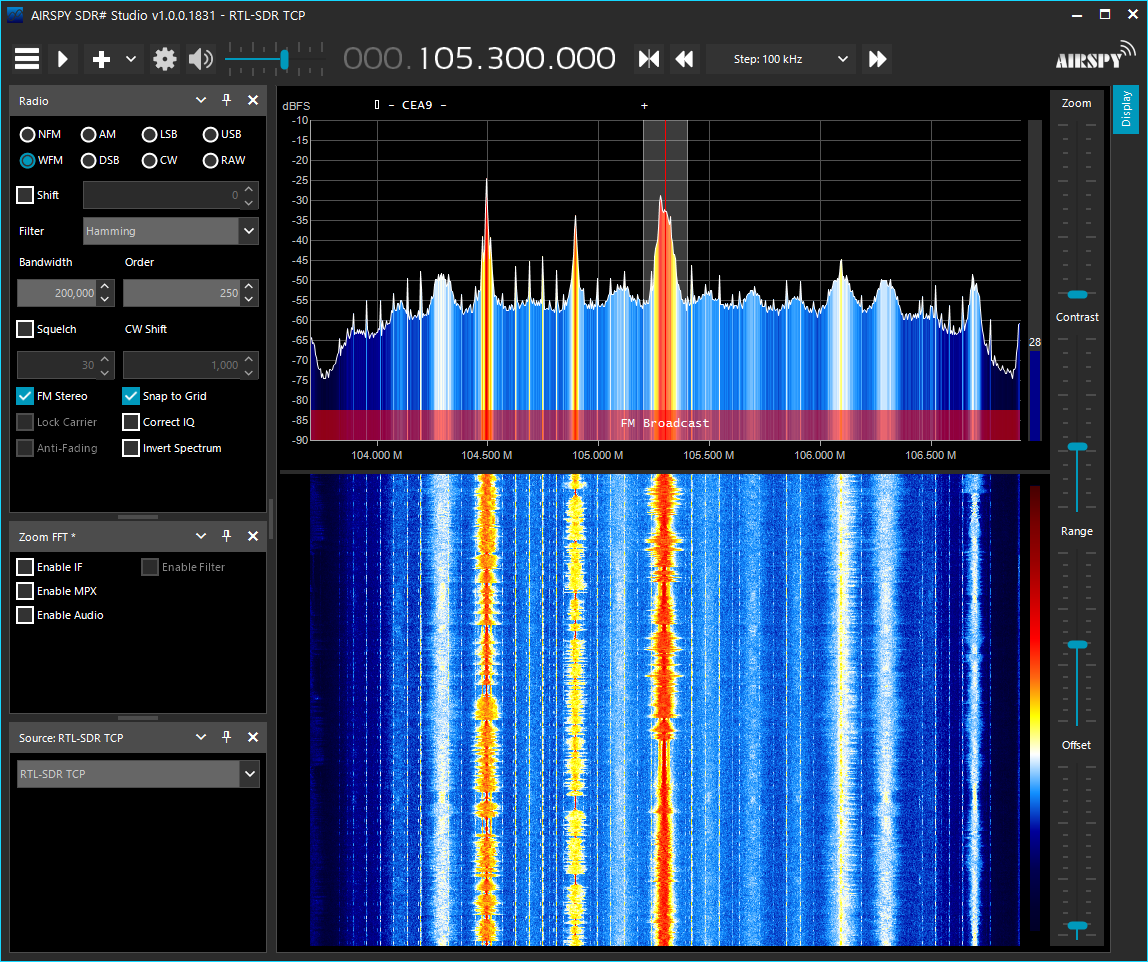
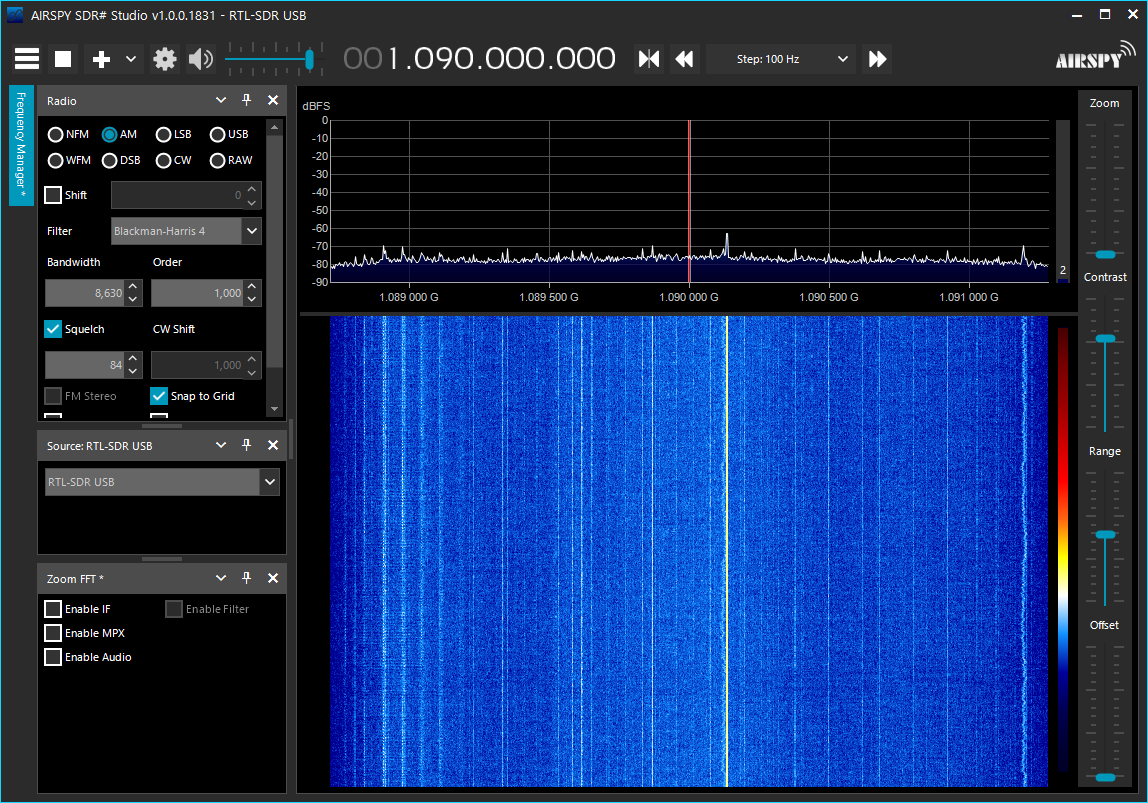
기본으로 제공된 내용을 사용해서 실행하는데 HackRF 장치가 맞지 않대서
| $ gnss-sdr --config_file=my.conf Initializing GNSS-SDR v0.0.11 ... Please wait. Logging will be written at "/tmp" Use gnss-sdr --log_dir=/path/to/log to change that. OsmoSdr arguments: hackrf,bias=1 gr-osmosdr 0.2.0.0 (0.2.0) gnuradio 3.8.1.0 built-in source types: file osmosdr fcd rtl rtl_tcp uhd miri hackrf bladerf rfspace airspy airspyhf soapy redpitaya freesrp Failed to use '0' as HackRF device index: not enough devices GNSS-SDR program ended. |
HackRF 용 옵션을 빼니 잘 작동한다. (나중에 찾아보니 GPS 신호 증폭을 위한 USB bias tee 기능 활성화 하는 옵션)
| $ cat my.conf [GNSS-SDR] ;######### GLOBAL OPTIONS ################## GNSS-SDR.internal_fs_sps=2000000 ;######### SIGNAL_SOURCE CONFIG ############ SignalSource.implementation=Osmosdr_Signal_Source SignalSource.item_type=gr_complex SignalSource.sampling_frequency=2000000 SignalSource.freq=1575420000 SignalSource.gain=40 SignalSource.rf_gain=40 SignalSource.if_gain=30 SignalSource.AGC_enabled=false SignalSource.samples=0 SignalSource.repeat=false ;# Next line enables the internal HackRF One bias (3.3 VDC) ;SignalSource.osmosdr_args=hackrf,bias=1 SignalSource.enable_throttle_control=false SignalSource.dump=false SignalSource.dump_filename=./signal_source.dat |
아래와 같이 신호를 잡으려고 하고 계속 lock이 안되는데, 지하철에서 시도해서 그런가?
| $ gnss-sdr --config_file=my.conf Initializing GNSS-SDR v0.0.11 ... Please wait. Logging will be written at "/tmp" Use gnss-sdr --log_dir=/path/to/log to change that. gr-osmosdr 0.2.0.0 (0.2.0) gnuradio 3.8.1.0 built-in source types: file osmosdr fcd rtl rtl_tcp uhd miri hackrf bladerf rfspace airspy airspyhf soapy redpitaya freesrp [INFO] [UHD] linux; GNU C++ version 9.2.1 20200304; Boost_107100; UHD_3.15.0.0-2build5 RtApiAlsa::getDeviceInfo: snd_pcm_open error for device (hw:0,0), Device or resource busy. Found Rafael Micro R820T tuner Using device #0 Realtek RTL2838UHIDIR SN: 00000001 Found Rafael Micro R820T tuner [R82XX] PLL not locked! Exact sample rate is: 2000000.052982 Hz [R82XX] PLL not locked! Actual RX Rate: 2000000.000000 [SPS]... Actual RX Freq: 1575420000.000000 [Hz]... PLL Frequency tune error 0.000000 [Hz]... Actual RX Gain: 40.200000 dB... Actual Bandwidth: 0.000000 [Hz]... Starting a TCP/IP server of RTCM messages on port 2101 The TCP/IP server of RTCM messages is up and running. Accepting connections ... Current receiver time: 1 s Current receiver time: 2 s Current receiver time: 3 s Current receiver time: 4 s Current receiver time: 5 s Tracking of GPS L1 C/A signal started on channel 7 for satellite GPS PRN 08 (Block IIF) Current receiver time: 6 s Current receiver time: 7 s Tracking of GPS L1 C/A signal started on channel 4 for satellite GPS PRN 25 (Block IIF) Current receiver time: 8 s Tracking of GPS L1 C/A signal started on channel 1 for satellite GPS PRN 22 (Block IIR) Tracking of GPS L1 C/A signal started on channel 6 for satellite GPS PRN 16 (Block IIR) Current receiver time: 9 s Current receiver time: 10 s Current receiver time: 11 s Current receiver time: 12 s Current receiver time: 13 s Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 27 (Block IIF) Current receiver time: 14 s Tracking of GPS L1 C/A signal started on channel 3 for satellite GPS PRN 13 (Block IIR) Tracking of GPS L1 C/A signal started on channel 5 for satellite GPS PRN 32 (Block IIF) Current receiver time: 15 s Current receiver time: 16 s Tracking of GPS L1 C/A signal started on channel 2 for satellite GPS PRN 04 (Block Unknown) Current receiver time: 17 s Current receiver time: 18 s Current receiver time: 19 s Current receiver time: 20 s Current receiver time: 21 s Loss of lock in channel 7! Current receiver time: 22 s Current receiver time: 23 s Loss of lock in channel 4! Current receiver time: 24 s Tracking of GPS L1 C/A signal started on channel 7 for satellite GPS PRN 20 (Block IIR) Loss of lock in channel 1! Loss of lock in channel 6! Tracking of GPS L1 C/A signal started on channel 6 for satellite GPS PRN 02 (Block IIR) Current receiver time: 25 s Tracking of GPS L1 C/A signal started on channel 4 for satellite GPS PRN 08 (Block IIF) Current receiver time: 26 s Loss of lock in channel 3! Tracking of GPS L1 C/A signal started on channel 3 for satellite GPS PRN 26 (Block IIF) Current receiver time: 27 s Current receiver time: 28 s Loss of lock in channel 0! Current receiver time: 29 s Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 29 (Block IIR-M) Current receiver time: 30 s Tracking of GPS L1 C/A signal started on channel 1 for satellite GPS PRN 15 (Block IIR-M) Loss of lock in channel 5! Current receiver time: 31 s Tracking of GPS L1 C/A signal started on channel 5 for satellite GPS PRN 10 (Block IIF) Current receiver time: 32 s Loss of lock in channel 2! Current receiver time: 33 s Current receiver time: 34 s Current receiver time: 35 s Tracking of GPS L1 C/A signal started on channel 2 for satellite GPS PRN 16 (Block IIR) Current receiver time: 36 s Loss of lock in channel 7! Current receiver time: 37 s Loss of lock in channel 4! Tracking of GPS L1 C/A signal started on channel 7 for satellite GPS PRN 27 (Block IIF) Current receiver time: 38 s Current receiver time: 39 s Current receiver time: 40 s Loss of lock in channel 6! Current receiver time: 41 s Tracking of GPS L1 C/A signal started on channel 4 for satellite GPS PRN 32 (Block IIF) Tracking of GPS L1 C/A signal started on channel 6 for satellite GPS PRN 04 (Block Unknown) Current receiver time: 42 s Loss of lock in channel 3! Current receiver time: 43 s Loss of lock in channel 5! Current receiver time: 44 s Tracking of GPS L1 C/A signal started on channel 3 for satellite GPS PRN 03 (Block IIF) Current receiver time: 45 s Loss of lock in channel 0! Current receiver time: 46 s Loss of lock in channel 1! Loss of lock in channel 4! Current receiver time: 47 s Loss of lock in channel 2! Tracking of GPS L1 C/A signal started on channel 4 for satellite GPS PRN 18 (Block IIR) Current receiver time: 48 s Tracking of GPS L1 C/A signal started on channel 5 for satellite GPS PRN 10 (Block IIF) Current receiver time: 49 s Tracking of GPS L1 C/A signal started on channel 2 for satellite GPS PRN 19 (Block IIR) Current receiver time: 50 s Current receiver time: 51 s Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 28 (Block IIR) Loss of lock in channel 0! Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 22 (Block IIR) Current receiver time: 52 s Tracking of GPS L1 C/A signal started on channel 1 for satellite GPS PRN 28 (Block IIR) Current receiver time: 53 s Loss of lock in channel 7! Current receiver time: 54 s Current receiver time: 55 s Tracking of GPS L1 C/A signal started on channel 7 for satellite GPS PRN 16 (Block IIR) Current receiver time: 56 s Current receiver time: 57 s Loss of lock in channel 6! Current receiver time: 58 s Tracking of GPS L1 C/A signal started on channel 6 for satellite GPS PRN 32 (Block IIF) Current receiver time: 59 s Current receiver time: 1 min 0 s Loss of lock in channel 3! Current receiver time: 1 min 1 s Tracking of GPS L1 C/A signal started on channel 3 for satellite GPS PRN 14 (Block IIR) Current receiver time: 1 min 2 s Current receiver time: 1 min 3 s Loss of lock in channel 4! Current receiver time: 1 min 4 s Loss of lock in channel 5! Current receiver time: 1 min 5 s Loss of lock in channel 2! Tracking of GPS L1 C/A signal started on channel 5 for satellite GPS PRN 08 (Block IIF) Current receiver time: 1 min 6 s Tracking of GPS L1 C/A signal started on channel 2 for satellite GPS PRN 26 (Block IIF) Tracking of GPS L1 C/A signal started on channel 4 for satellite GPS PRN 05 (Block IIR-M) Current receiver time: 1 min 7 s Loss of lock in channel 0! Current receiver time: 1 min 8 s Loss of lock in channel 1! Current receiver time: 1 min 9 s Current receiver time: 1 min 10 s Loss of lock in channel 7! Current receiver time: 1 min 11 s Tracking of GPS L1 C/A signal started on channel 1 for satellite GPS PRN 31 (Block IIR-M) Loss of lock in channel 1! Current receiver time: 1 min 12 s Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 06 (Block IIF) Loss of lock in channel 0! Current receiver time: 1 min 13 s Tracking of GPS L1 C/A signal started on channel 7 for satellite GPS PRN 22 (Block IIR) Tracking of GPS L1 C/A signal started on channel 1 for satellite GPS PRN 03 (Block IIF) Current receiver time: 1 min 14 s Loss of lock in channel 6! Current receiver time: 1 min 15 s Tracking of GPS L1 C/A signal started on channel 0 for satellite GPS PRN 01 (Block IIF) Current receiver time: 1 min 16 s Current receiver time: 1 min 17 s |
[링크 : https://gnss-sdr.org/docs/tutorials/gnss-sdr-operation-realtek-rtl2832u-usb-dongle-dvb-t-receiver/]
gnss의 경우 rtl_tcp를 통해 원격지의 정보를 받아올 수 도 있는 듯.
| In case of using a Zarlink's RTL2832 based DVB-T receiver, you can even use the rtl_tcp I/Q server in order to use the USB dongle remotely. In a terminal, type: $ rtl_tcp -a 127.0.0.1 -p 1234 -f 1575420000 -g 0 -s 2000000 and use the following configuration: ;######### SIGNAL_SOURCE CONFIG ############ SignalSource.implementation=RtlTcp_Signal_Source |
[링크 : https://github.com/gnss-sdr/gnss-sdr#build-osmosdr-support-optional]
'프로그램 사용 > rtl-sdr' 카테고리의 다른 글
| NEO-6M GPS 안테나 (0) | 2021.12.23 |
|---|---|
| rtl sdr gps gnss-sdr 실패 (0) | 2021.12.22 |
| sdr noaa 준비 (0) | 2021.12.21 |
| RTL-SDR NOAA 위성 수신하기 2차 시도도 반쪽 성공 (2) | 2021.12.19 |
| sdr gps linux (0) | 2021.12.19 |