설치 중에는 딱히 v2 라는 이야기가 없어서 실망(?)

먼가.. 먼가.. 밋밋하게 끝 -_-

SDK v1.8 과 v2.0 이라..

장치 관리자에는 WDF KinectSensor interface 라고 인식된다.

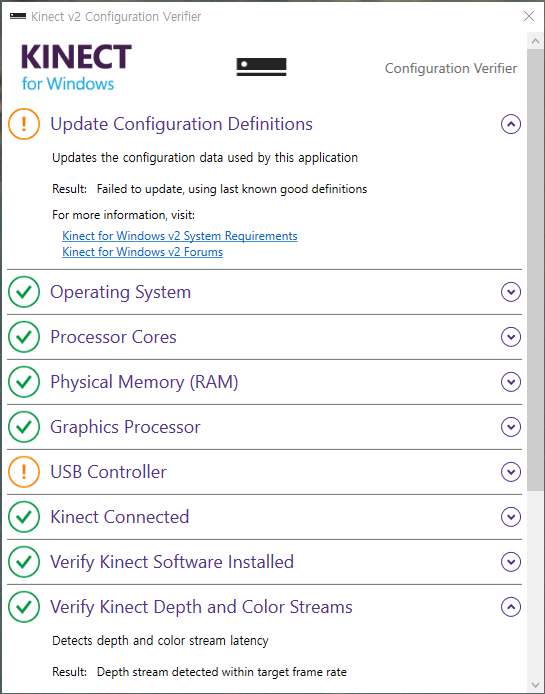
설정 확인용 프로그램
처음에 kinect studio를 실행해도 영상이 획득이 안되길래 해봤는데
별 도움은 안되었지만.. 아무튼 USB3.0으로 정상적으로 접속되어야
Kinect Depth and Color Streams 등이 녹색으로 체크가 된다.
최소한 USB 포트가 2.0인지 3.0인지 정상적으로 연결된걸 확인했으니 도움은 된듯


'프로그램 사용 > kinect' 카테고리의 다른 글
| kinect v2 / freenect 실패 (0) | 2024.07.09 |
|---|---|
| xbox one S / 기본형? (0) | 2024.06.25 |
| kinect2 도착 (0) | 2024.06.20 |
| 오늘의 충동구매 kinect v2 for windows (0) | 2024.06.19 |
| kinect skeleton tracking (0) | 2022.05.02 |














