하드웨어/Display 장비
nvidia tensor core
구차니
2026. 5. 21. 11:32
싼거 샀다 피보는 중 ㅋㅋㅋ
cuda core는 fp32나 fp64 행렬 단일 연산(곱/덧셈 등..) 에 특화 되어있고
tensor core는 복잡 정밀도의 (AxB) + C 에 대한 연산에 특화되어있는 것으로 보인다.
cuda core 로는
AxB 를 먼저 수행하고(fp32) 거기에 +C를 해서 두번의 연산이 필요했다면
tensor 코어는 (A x B) + C 에 대해서 한번에 하드웨어 적으로 퉤~(물론 정밀도 희생)
복합정밀도, 복합 행렬 연산(FMA - Fused Multiply Add)

[링크 : https://comsys-pim.tistory.com/5]
[링크 : https://youtu.be/h9Z4oGN89MU?t=1611]
+
2026.05.22
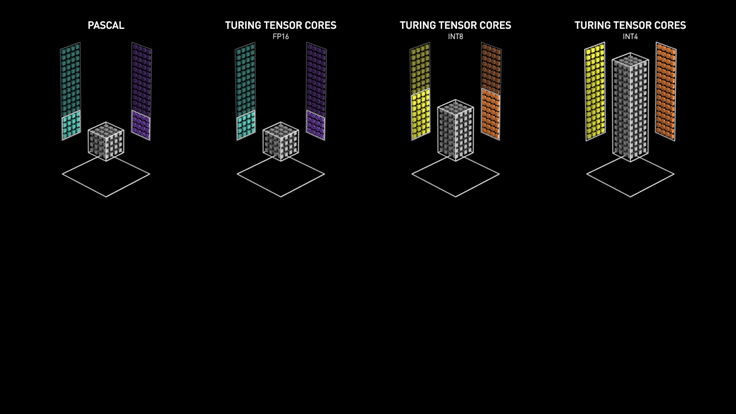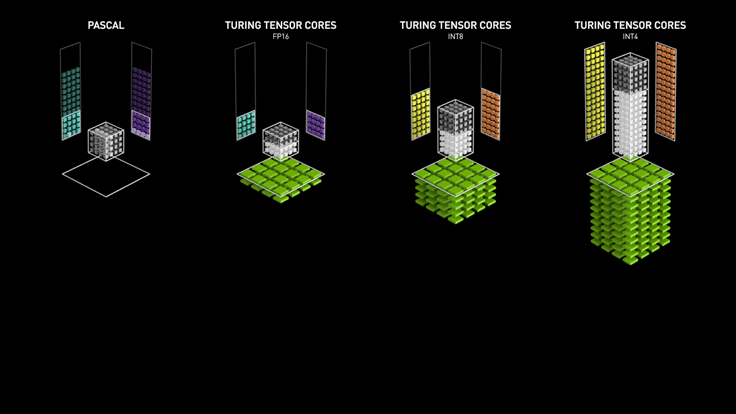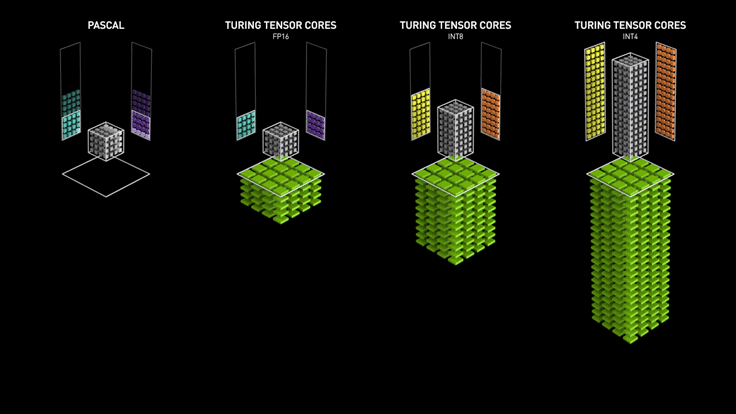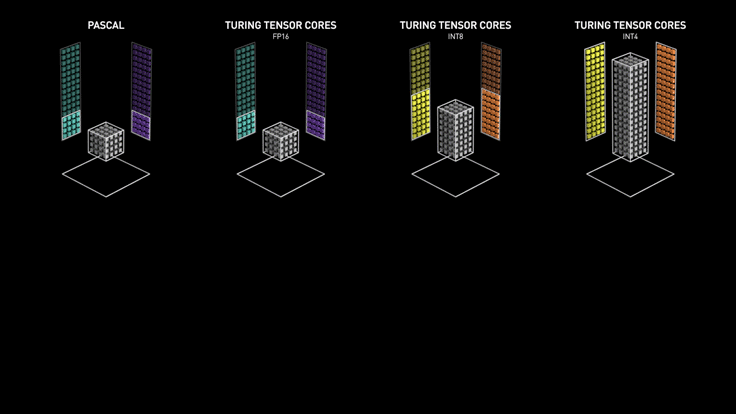
최소한 암페어(30 시리즈) 는 가야 BF16 지원하니까 정상적인(?) 성능이 나올 듯.
|
[링크 : https://blogs.novita.ai/ko/what-are-tensor-cores-the-key-to-supercharging-your-ai-models/]